
Here is the step by step procedure to configure and create iBOTS.
1. Create Oracle BI Scheduler Tables
Execute the ‘SAJOBS.Oracle.sql’ file located on ‘..\OracleBI\server\Schema’ to the schema where you like your Scheduler table has to be . The scripts will be different for the different database. “SAJOBS.Oracle.sql” is for Oracle database.
2. Configuring Oracle BI Scheduler Administrator
We need to have a Scheduler Administrator in the Oracle bi Repository(RPD) and this user must have the membership in Administrators group.
If you do not want to create a new administrator for Scheduler, you can set the Scheduler Administrator credentials to those of the Oracle BI user or Administrator that exists in the repository.

3. Configure BI Scheduler Schema in Job Manger
In RPD Go to Manage --> Jobs --> Job Manger --> Configuration Options and set the following information.




Open the instanceconfig.xml file located under ‘..\OracleBIData\web\config’.
Between the <ServerInstance></ServerInstance> tags , specify the following “Alerts” tag.
(If already existed no need to add)

If the Scheduler port is not “9705”, we have to specify the changed one as follows..
<Alerts>
<ScheduleServer>CLIENT21:<changed port></ScheduleServer>
</Alerts>
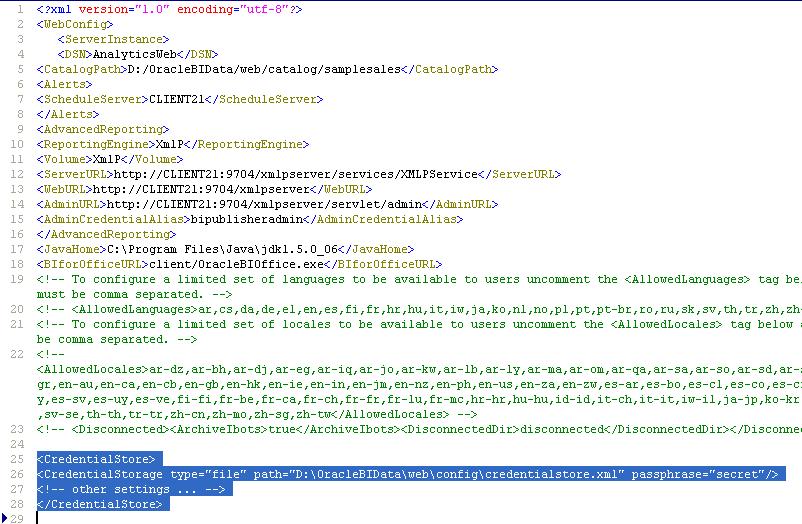
5. Configure BI Presentation Services Credential Store
Oracle BI Presentation Services must be able to identify the Scheduler administrator and obtain the credentials to establish a connection with the Scheduler. Presentation Services stores the credentials that it uses in a Presentation Services Credential Store. The Scheduler administrator credentials must be added to the credential store, under the alias admin. To obtain the Scheduler Administrator credentials, Oracle BI Presentation Services searches the credential store for a username-password credential with the alias admin.
Use the following procedure to add the Scheduler administrator credentials to the Presentation Services Credential Store with the admin alias.
This procedure adds the Scheduler administrator credentials to a proprietary XML file credential store called credentialstore.xml. The default location of this file is ‘..\OracleBIData\web\config’ on Windows .
Execute the CryptoTools utility to add the Scheduler Administrator credentials to the Presentation Services Credential Store :---- Open “Command Prompt” and go to the following path where CryptoTools utility is located: “D:\OracleBI\web\bin”
Exetute the following command:
Enter the details it asks as follows:
>Credential Alias: admin
>Username: SchedulerAdmin
>Password: SchedulerAdmin
>Do you want to encrypt the password? y/n (y): y
>Passphrase for encryption: secret
>Do you want to write the passphrase to the xml? y/n (n): n
>File “D:\OracleBIData/web/config/credentialstore.xml” exists. Do you want to
overwrite it? y/n (y): y
The CryptoTools utility updates the credentialstore.xml file .

6. Configuring Oracle BI Presentation Services to Identify the Credential Store
Oracle BI Presentation Services must be directed to the credential store that contains the Scheduler administrator credentials. This is done by setting parameters in the Oracle BI Presentation Services configuration file, instanceconfig.xml.
7. Create iBot in BI Presentation Interface
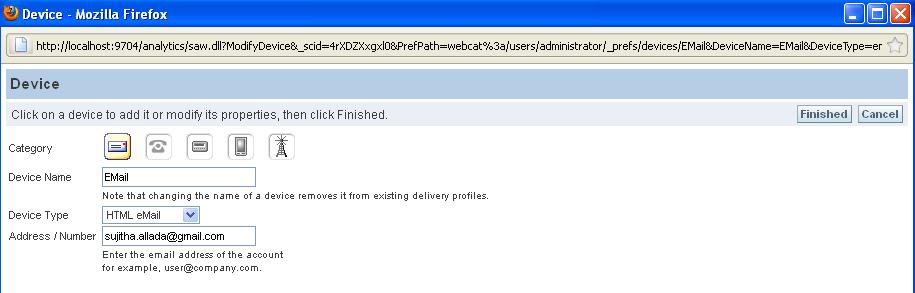
Add Devices to Email and put email address where you want to receive the deliverable content.

Set content Priority to the required option.

Add “SchedulerAdmin” to “Presentation Server Administrators” Group.

Change the permission for Delivers from ‘Manage Privileges’ as below:

Click on Delivers and Create new iBot .Set Schedule to immediate or set the time on which you want the ibot to deliver.


Set recipients as Me and additionally you can choose from user groups listed here .Select the deliverable content to Dashboard or Report .Select Destination to ‘Email’


After saving the iBot, it is ready to deliver.










